




为了克服这些局限,研究人员正在探索新型的网络架构和协议设计。他们试图通过解耦应用程序与网络资源,实现更灵活的资源分配和更高效的数据处理。例如,虚拟网络系统(VNS)层的引入,允许应用程序通过标准化的接口与网络交互,同时确保数据传输的语义正确性。这一层的设计理念是让网络通信更加模块化,便于不同应用和内核程序的协同工作。
在NetChannel的设计中,NetDriver层起到了关键作用。它通过channel抽象将网络和远程服务器抽象为一个多队列设备,实现了包处理与单个应用程序和CPU核心的解耦。这样,一个核心上的应用程序可以同时映射到多个channel,从而提高资源利用率和网络吞吐量。
网络调度器是另一个重要的组成部分,它负责隔离延迟敏感的应用程序和带宽密集型的应用程序。通过精细的流量控制,网络调度器确保延迟敏感的应用程序能够在与高带宽应用竞争时,依然保持微秒级的尾部延迟,而带宽密集型应用则能充分利用剩余带宽。
除了重新设计网络堆栈,无服务器计算框架如SPRIGHT也吸引了研究者的注意。SPRIGHT旨在通过轻量级、事件驱动处理和共享内存技术,提高无服务器函数链的性能。通过使用eBPF和共享内存,SPRIGHT在吞吐量、延迟和CPU使用率方面相比传统的无服务器框架展现了显著的性能优势。
在视频流传输领域,研究也在不断推进。NeuroScaler项目致力于通过优化神经超分辨率计算和视频编码,实现高分辨率视频流的实时传输。NeuroScaler通过选择合适的锚帧和有效地分配计算资源,显著降低了计算和传输负载,提高了整体性能。
阿里巴巴的LiveNet项目则提供了一个基于扁平CDN结构的低延迟视频传输网络。LiveNet通过灵活的节点角色分配、集中协调的控制器和创新的流转发机制,大幅缩短了传输路径,降低了延迟,并提高了用户可感知的体验。
GSO-Simulcast是针对大规模视频会议系统的研究成果,它通过全局信息协调和流策略管理,实现了不同网络状态下参与者之间的协调,以及灵活的流策略配置,有效地提高了视频会议的质量和用户体验。
综上所述,网络通信技术正朝着更加灵活、高效和可扩展的方向发展。新型网络架构和协议设计不仅在理论层面上提供了创新的解决方案,而且在实际应用中展现出巨大的潜力。随着技术的不断进步和应用场景的日益丰富,我们有理由相信,未来的网络通信将更加智能、高效,更好地满足不断增长的需求。
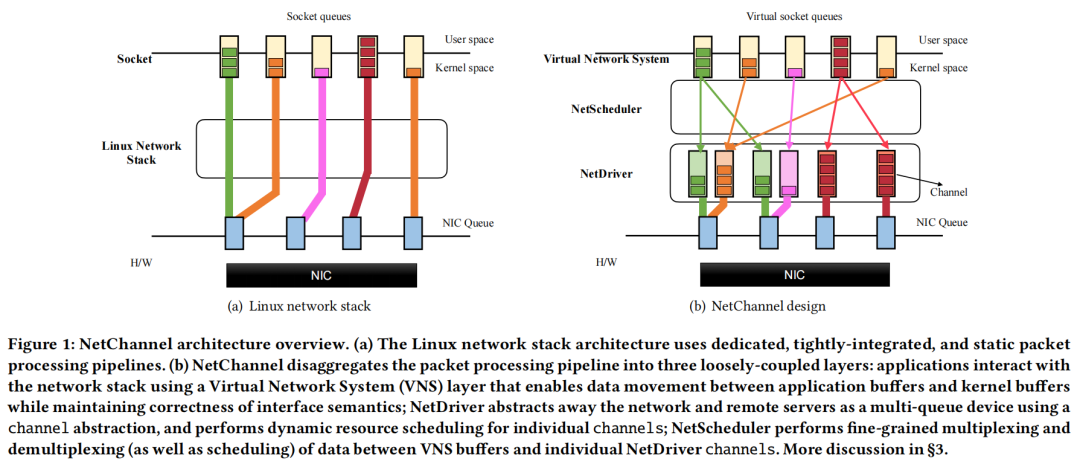 >设计 如图1(b)所示,NetChannel将今天的网络堆栈中紧密集成的包处理管道分解为三个松散
耦合的层。
虚拟网络系统(VNS):应用程序与提供标准化
接口的VNS层交互。VNS层支持应用程序和内核程序之间的数据传输,同时确保接口语义的正确性(例如,流接口的有序传递)。
NetChannel的核心是NetDriver层:它使用channel抽象将网络和远程服务器抽象为一个多队列设备。特别是,NetDriver层将包处理从单个应用程序和core解耦:一个core上的应用程序读取/写入的数据可以映射到一个或多个channel,而不破坏应用程序语义。每个通道都实现了协议规范功能独立,可以动态映射到一个底层硬件队列,和任何一对服务器之间的通道的数量可以扩展独立于这些服务器上运行的应用程序的数量和个人应用程序使用的核心的数量。
网络调度器:它将延迟敏感的应用程序与吞吐量绑定的应用程序隔离:网络通道使延迟敏感的应用程序能够实现微秒规模的尾部延迟,同时允许带宽密集型的应用程序几乎完美地使用剩余带宽。 NetChannel优势在于简单,容易实现,同时能够提升当前网络堆栈的性能,且独立于网络堆栈的位置——内核、用户空间或硬件,可以在微内核风格的用户空间堆栈上实现其设计。作者选择Linux内核只是因为它的成熟、稳定性和广泛的部署。
>性能
>设计 如图1(b)所示,NetChannel将今天的网络堆栈中紧密集成的包处理管道分解为三个松散
耦合的层。
虚拟网络系统(VNS):应用程序与提供标准化
接口的VNS层交互。VNS层支持应用程序和内核程序之间的数据传输,同时确保接口语义的正确性(例如,流接口的有序传递)。
NetChannel的核心是NetDriver层:它使用channel抽象将网络和远程服务器抽象为一个多队列设备。特别是,NetDriver层将包处理从单个应用程序和core解耦:一个core上的应用程序读取/写入的数据可以映射到一个或多个channel,而不破坏应用程序语义。每个通道都实现了协议规范功能独立,可以动态映射到一个底层硬件队列,和任何一对服务器之间的通道的数量可以扩展独立于这些服务器上运行的应用程序的数量和个人应用程序使用的核心的数量。
网络调度器:它将延迟敏感的应用程序与吞吐量绑定的应用程序隔离:网络通道使延迟敏感的应用程序能够实现微秒规模的尾部延迟,同时允许带宽密集型的应用程序几乎完美地使用剩余带宽。 NetChannel优势在于简单,容易实现,同时能够提升当前网络堆栈的性能,且独立于网络堆栈的位置——内核、用户空间或硬件,可以在微内核风格的用户空间堆栈上实现其设计。作者选择Linux内核只是因为它的成熟、稳定性和广泛的部署。
>性能
-
使单个应用程序线程饱和数百千兆访问链路带宽;

-
支持具有核数的小消息处理的近线性可伸缩性,独立于应用程序线程数;
-
支持隔离对延迟敏感的应用程序,允许它们即使在与以近线速率运行的吞吐量绑定的应用程序竞争时也能保持us-scale的尾延迟。
-
优点
-
不足
SPRIGHT: Extracting the Server from Serverless Computing High-Performance eBPF-based Event-driven, Shared-Memory Processing
Shixiong Qi, Leslie Monis, Ziteng Zeng, Ian-chin WANg, K. K. Ramakrishnan (University of California, Riverside)
>背景与问题 这篇文章来自California的研究者。它设计了一个一种轻量级、高性能、响应式无服务器(Serverless)框架——SPRIGHT。无服务器计算越来越受欢迎,因为用户只需要开发他们的应用程序,而无需关心底层 操作系统和硬件基础设施。但是对于云服务提供商来说,如何确保满足服务质量要求(SLO)是一项复杂的工作。其中出现的困难主要有两个: (1)重型的无服务器组件:为了实现具有广泛功能支持的跨功能服务网格层(例如指标收集和缓冲,促进无服务器网络和编配等),每个函数仓(function pod)都会有一个专用的sidecar代理组件来帮助建立。但是该组件是重型的,需要持续运行并产生过多的开销。并且对于非常见的协议(例如MQTT, CoAP等),也需要额外的重型组件来适配,也会导致大量资源开销。 (2) 函数链的数据平面性能较差:现代的云架构为了提高灵活性,借助独立于平台的 通信技术(如HTTP/REST A PI),将单个应用程序分解为多个松耦合、链接的函数。但是,这涉及到上下文切换、序列化和反序列化以及数据复制开销。目前的设计还严重依赖于内核协议栈来处理路由和在功能舱之间转发网络数据包,所有这些都会影响性能。虽然灵活性提升了,但是性能开销却仍是一个负担。函数间产生的复杂数据管道为函数链增加了更多的 网络通信。所有这些都会导致数据平面性能较差(吞吐量较低,延迟较高),影响服务水平目标(SLOs)。 下图为作者研究了几个专有和开源的无服务器平台的设计后,开发的一个通用抽象模型。当客户端发送消息时,在经过网关后(①),在前端代理/消息代理中排队(②)。代理会将消息发送到第一个函数仓,但是会先经过sidecar代理(③)。第一个函数处理完成后,会发往代理排队进入下一个函数仓,但还是要先经过sidecar代理(④)。转交到下个函数仓,按③④的步骤,沿着函数链反复执行下去(⑤)。由此图就可以看出,无服务器函数链产生的额外开销是非常巨大的(除函数仓的user cont ainer外都是)。 >设计 作者以开源项目Knative作为基础平台开始。使用事件驱动处理和共享内存来提升性能,并广泛使用eBPF进行联网和监控。eBPF是一个内核内的轻量级虚拟机,它可以插入/从内核中插入,具有相当的灵活性、效率和可配置性。 下图显示了SPRIGHT的总体架构。主要包括以下几个内容:
>设计 作者以开源项目Knative作为基础平台开始。使用事件驱动处理和共享内存来提升性能,并广泛使用eBPF进行联网和监控。eBPF是一个内核内的轻量级虚拟机,它可以插入/从内核中插入,具有相当的灵活性、效率和可配置性。 下图显示了SPRIGHT的总体架构。主要包括以下几个内容:
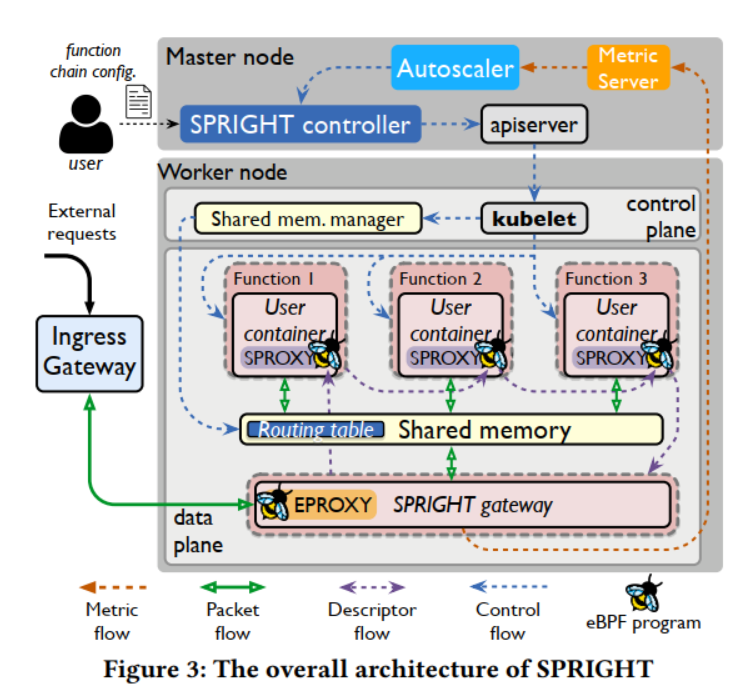 SPRIGHT控制器用来协调与编配引擎(即K8s和Knative)协同工作的函数的控制平面。在K8s主节点中运行,与k8s运作在每个worker节点上的进程合作,对函数仓的生命周期进行管理。此外,与k8s的调度器一起工作,以确定函数链的规模和函数链在适当的工作节点上的放置位置。给定一个来自用户的函数链创建请求,SPRIGHT控制器为函数链创建并分配必要的控制和数据平面组件,包括共享内存管理器和SPRIGHT网关,并根据用户配置启动函数链中的函数。 SPRIGHT网关是为了灵活管理SPRIGHT中函数链的进出流量,避免在函数链中重复处理协议。充当了函数链的反向代理,以合并协议处理。它拦截对函数链的传入请求,并将有效负载复制到共享内存区域。这允许在链内进行零拷贝处理,避免不必要的序列化/反序列化和协议栈处理。SPRIGHT网关是一个轻量级组件,内存占用相对较小,CPU消耗也不是一个重要的问题。 为了消除额外的网络组件对函数链的影响,作者设计了直接功能路由(DFR)。DFR利用共享内存并利用eBPF映射提供的可配置性。DFR允许动态更新路由规则,并使用共享内存直接在函数之间传递数据。 设计了一个轻量级的、事件驱动的代理(EPROXY和SPROXY),它使用eBPF来构造服务网格,而不是像Knative那样使用与每个函数实例关联的连续运行的队列代理。因此,我们减少了大量的处理开销。
>性能 与Knative相比,SPRIGHT通过大量使用基于ebp的事件驱动能力以及高性能的共享内存处理,实现了高达5倍的吞吐量提高,53倍的延迟减少,以及27倍的CPU使用节省。 与使用DPDK提供共享内存和零拷贝交付的环境相比,SPRIGHT实现了具有竞争力的吞吐量和延迟,同时消耗的CPU资源减少了11倍。 此外,对于
物联网应用中常见的间歇请求到达,与Knative使用“预热”功能相比,SPRIGHT仍然将平均延迟提高了16%,同时减少了41%的CPU周期。
>个人观点 SPRIGHT是一个无服务器函数链框架,通过对零拷贝、基于eBPF代理和共享内存的系统优化的良好组合,相对于现有的开源无服务器框架,它提供了大量的CPU、延迟和启动时间改进。此外,本文贡献了eBPF中高性能软件数据路径的设计和实现,该路径非常适合跨节点中运行的函数链处理请求调用的路由和转发。
SPRIGHT控制器用来协调与编配引擎(即K8s和Knative)协同工作的函数的控制平面。在K8s主节点中运行,与k8s运作在每个worker节点上的进程合作,对函数仓的生命周期进行管理。此外,与k8s的调度器一起工作,以确定函数链的规模和函数链在适当的工作节点上的放置位置。给定一个来自用户的函数链创建请求,SPRIGHT控制器为函数链创建并分配必要的控制和数据平面组件,包括共享内存管理器和SPRIGHT网关,并根据用户配置启动函数链中的函数。 SPRIGHT网关是为了灵活管理SPRIGHT中函数链的进出流量,避免在函数链中重复处理协议。充当了函数链的反向代理,以合并协议处理。它拦截对函数链的传入请求,并将有效负载复制到共享内存区域。这允许在链内进行零拷贝处理,避免不必要的序列化/反序列化和协议栈处理。SPRIGHT网关是一个轻量级组件,内存占用相对较小,CPU消耗也不是一个重要的问题。 为了消除额外的网络组件对函数链的影响,作者设计了直接功能路由(DFR)。DFR利用共享内存并利用eBPF映射提供的可配置性。DFR允许动态更新路由规则,并使用共享内存直接在函数之间传递数据。 设计了一个轻量级的、事件驱动的代理(EPROXY和SPROXY),它使用eBPF来构造服务网格,而不是像Knative那样使用与每个函数实例关联的连续运行的队列代理。因此,我们减少了大量的处理开销。
>性能 与Knative相比,SPRIGHT通过大量使用基于ebp的事件驱动能力以及高性能的共享内存处理,实现了高达5倍的吞吐量提高,53倍的延迟减少,以及27倍的CPU使用节省。 与使用DPDK提供共享内存和零拷贝交付的环境相比,SPRIGHT实现了具有竞争力的吞吐量和延迟,同时消耗的CPU资源减少了11倍。 此外,对于
物联网应用中常见的间歇请求到达,与Knative使用“预热”功能相比,SPRIGHT仍然将平均延迟提高了16%,同时减少了41%的CPU周期。
>个人观点 SPRIGHT是一个无服务器函数链框架,通过对零拷贝、基于eBPF代理和共享内存的系统优化的良好组合,相对于现有的开源无服务器框架,它提供了大量的CPU、延迟和启动时间改进。此外,本文贡献了eBPF中高性能软件数据路径的设计和实现,该路径非常适合跨节点中运行的函数链处理请求调用的路由和转发。
NeuroScaler: neural video enhancement at scale
Hyunho Yeo, Hwijoon Lim, Jaehong Kim, Youngmok Jung, Juncheol Ye, Dongsu Han (KAIST)
这篇文章来自KAIST的研究者。本文主要解决的内容是在直播 视频流传输的场景下,采用传统的神经增强方法(Neural enhancement)实现高分辨率的视频流传输时,神经超分辨率(Neural super-resolution)计算开销过大,无法满足实时直播需求的问题。本文的是通过提供恰当的超分辨率帧计算方案与服务端的编码方案,优化整体传输性能与视频质量。 >背景与问题 当今视频流的传输过程中,人们对于高分辨率的视频需求日益增长。而随着网络技术的迭代,人们对于直播视频流的质量有了更多的期待。但是,高清视频的传输很大程度上依赖于上行带宽,因此,传统的技术多采用DNN技术,从较低的分辨率图像中获取较高的分辨率。当前的技术具有以下几个特点: 上行带宽较低:视频流需要从上行带宽中传输到媒体服务器,并分发给其他接收者。但由于上行带宽较低,往往无法提供较高的视频流质量。 超分辨率技术:超分辨率技术是指将低分辨率对应物生成高分辨率图像的技术。现有的超分辨率技术大多使用深度 神经网络 (DNN),学习低分辨率到高分辨率低映射。 锚帧选取:锚帧是指应用超分辨率技术的帧。因为对帧进行超分辨率推理带来极大的开销,因此我们无法对每一个帧进行推理。所以,从视频流的一系列帧中选取锚帧,利用锚帧重建高分辨率视频图像是一种合理的方式。 因为上行带宽较低,所以我们需要采用超分辨率技术进行视频流质量的提升。但是,超分辨率技术带来巨大的计算开销,因此,我们不能对每一个流进行推理,而是应该选择锚帧进行辅助重建。这也就带来了一系列的问题:1)锚帧的选取很大程度上影响着视频流的质量,不合理的锚帧会导致重建后的视频质量较低,因此,合适的实时锚帧选择方式能极大改善系统的质量。2)锚帧的计算开销是异构的,这也意味着如果对于锚帧计算资源分配不恰当,会导致整体性能的降低。3)媒体服务器上对帧的编码也会带来极大的计算开销。 >设计 本文作者认为,合适的锚帧选择可以提高视频重建的质量,而视频流的编码则是制约整体性能的重要瓶颈。当前的设计面临着三个主要的挑战:1)图像增强的高计算开销。2)编码带来的额外时延。3)在计算资源上的分配失效,无法带来满意的表现。此作者提出了三个部分的改进,分别是1)锚帧的调度,即选取合适的锚帧,利用该锚帧可以获取更好的视频重建表现。2)为锚帧有效地分配计算资源。3)以及锚帧的增强设计,即使用合适的方法,在超分辨率编码阶段降低计算开销。其整体的架构如下图所示: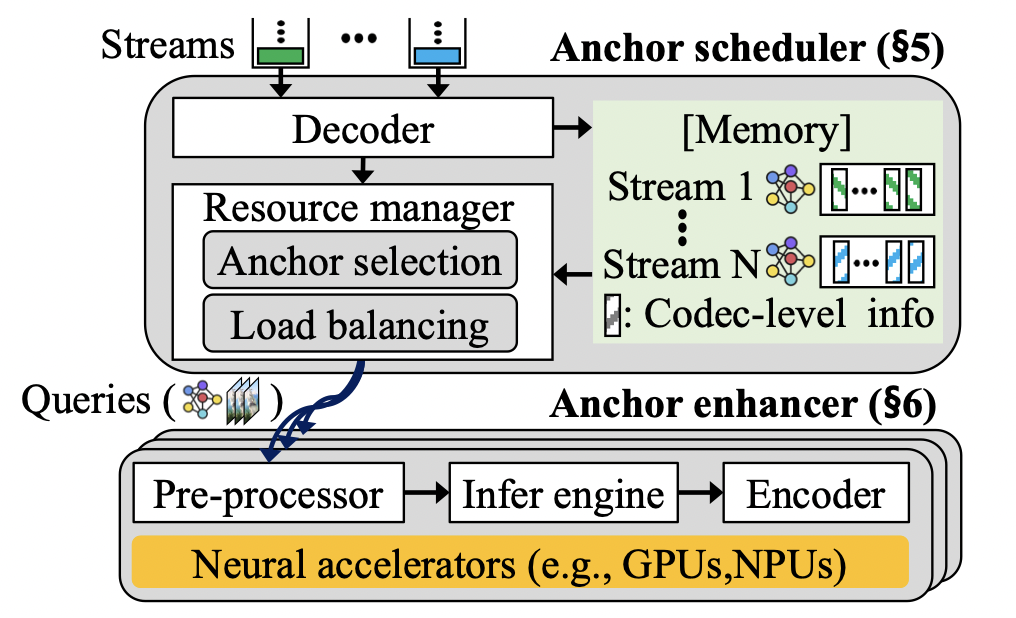 无推断锚帧选取:锚帧的增益可以不经过实际的神经推理即可获取。当我们不断使用超分辨率进行图像的重建,因为图像之间的残差,导致重建后的质量损失。另一方面,文章观察到增益和残差具有一定的相关性,因此,文章通过残差的计算,选取合适的锚帧,而不需要进行具有极大计算开销都神经推理。
锚帧计算资源分配:锚帧的计算开销和增益都是异构并会随着时间变化的,因此,简单的平均分配并不能带来优秀的表现。因此,计算资源的调度应该从锚帧的角度思考。本文提出了一个锚帧的选取
算法,即从之前计算获得的锚帧集合中,按照顺序尽可能多的选取一部分锚帧,同时这些锚帧的推理时延需求要满足一定的限制。在此之后,将锚帧进行分组,并对每组分配计算资源。
编码开销限制:文章指出,非锚帧在接收端仍能以较低的计算开销进行重建,因此,在媒体服务端,没必要对非锚帧进行编码,而锚帧所占比例较低,这极大降低了编码的开销。而在解码端,该方法只引入了18% 的额外计算开销,这与编码开销的降低相比,是可以接受的。
GPU上下文切换:除了上述设计之外,文章还针对推理框架的切换带来的开销,引入了模型预优化与内存预分配,提高了整体的性能表现。
>性能
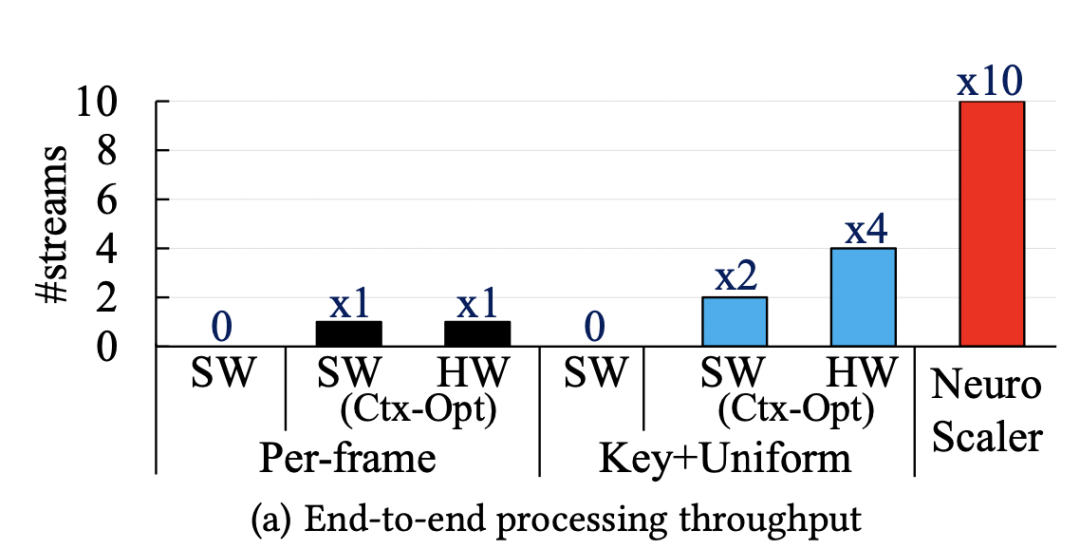
端对端吞吐量:如下图所示,NeuroScaler overview相对于每一帧推断以及其他选取的对比,吞吐量提高了10x和2x-5x。
无推断锚帧选取:锚帧的增益可以不经过实际的神经推理即可获取。当我们不断使用超分辨率进行图像的重建,因为图像之间的残差,导致重建后的质量损失。另一方面,文章观察到增益和残差具有一定的相关性,因此,文章通过残差的计算,选取合适的锚帧,而不需要进行具有极大计算开销都神经推理。
锚帧计算资源分配:锚帧的计算开销和增益都是异构并会随着时间变化的,因此,简单的平均分配并不能带来优秀的表现。因此,计算资源的调度应该从锚帧的角度思考。本文提出了一个锚帧的选取
算法,即从之前计算获得的锚帧集合中,按照顺序尽可能多的选取一部分锚帧,同时这些锚帧的推理时延需求要满足一定的限制。在此之后,将锚帧进行分组,并对每组分配计算资源。
编码开销限制:文章指出,非锚帧在接收端仍能以较低的计算开销进行重建,因此,在媒体服务端,没必要对非锚帧进行编码,而锚帧所占比例较低,这极大降低了编码的开销。而在解码端,该方法只引入了18% 的额外计算开销,这与编码开销的降低相比,是可以接受的。
GPU上下文切换:除了上述设计之外,文章还针对推理框架的切换带来的开销,引入了模型预优化与内存预分配,提高了整体的性能表现。
>性能
端对端吞吐量:如下图所示,NeuroScaler overview相对于每一帧推断以及其他选取的对比,吞吐量提高了10x和2x-5x。
 资源开销:如以下两幅图所示,NeuroScaler的资源开销,相较于其他的方案都较为低廉,能够很好地满足性能的需求。
资源开销:如以下两幅图所示,NeuroScaler的资源开销,相较于其他的方案都较为低廉,能够很好地满足性能的需求。
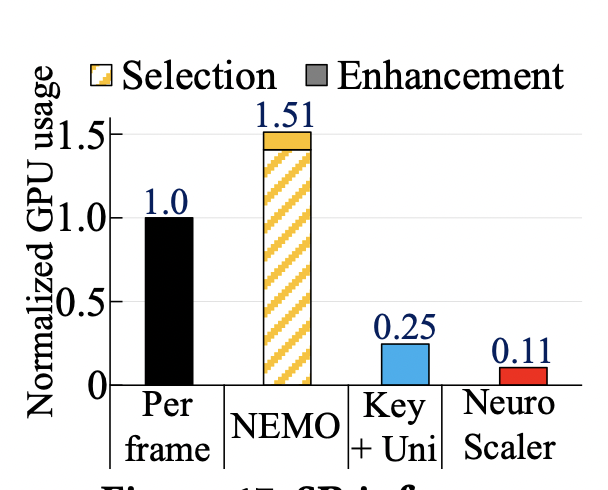
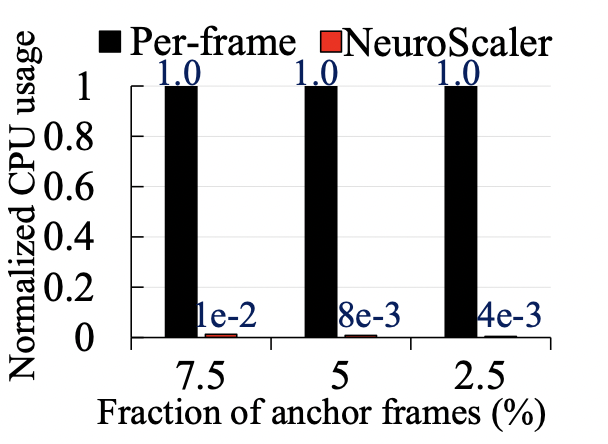 >个人观点 本文作者主要解决的是当前直播视频流传输遇到的主要问题。在计算资源与传输资源紧张的情况下,通过选取合适的计算方法与编码思路,可以极大减轻计算与传输负载。本文便采用恰当的锚帧选取算法,以较小的计算资源获得较为优异的表现。同时,本文以接收端的解码时间为代价,牺牲了一部分接收端的解码速度,极大增强了媒体服务器的速度,即将整体负载分散到多个独立的运算端上,从而获得整体性能的提升。
>个人观点 本文作者主要解决的是当前直播视频流传输遇到的主要问题。在计算资源与传输资源紧张的情况下,通过选取合适的计算方法与编码思路,可以极大减轻计算与传输负载。本文便采用恰当的锚帧选取算法,以较小的计算资源获得较为优异的表现。同时,本文以接收端的解码时间为代价,牺牲了一部分接收端的解码速度,极大增强了媒体服务器的速度,即将整体负载分散到多个独立的运算端上,从而获得整体性能的提升。
LiveNet: a low-latency video transport network for large-scale live streaming
Jinyang Li, Zhenyu Li (ICT, CAS), Ri Lu, Kai Xiao, Songlin Li, Jufeng Chen, Jingyu Yang, Chunli Zong, Aiyun Chen (Alibaba Group), Qinghua Wu (ICT, CAS), Chen Sun (Alibaba Group), Gareth Tyson (Queen Mary University of London), Hongqiang Harry Liu (Alibaba Group)
本文来自阿里巴巴和中科院计算所等机构的研究者,主要报道了作者在阿里云的直播服务LiveNet的建设和运营方面所做的工作。 >背景与问题 随着新冠肺炎疫情在全球范围内蔓延,直播已经成为日常生活的必需品。随着新的低延迟直播用例的出现(如 电子商务、工作、娱乐游戏),用户数量显著增长。随着用户期望的增长,底层传输系统的灵活性和可扩展性受到了挑战。 作为全球主要的CDN提供商之一,阿里巴巴的CDN拥有众多的直播应用(如淘宝的电商直播)。多年来,这些应用程序在很大程度上得到了阿里巴巴第一代分层视频传输网络的支持(见下图)。在该网络中,流被传输到一个中央系统进行视频加工,然后分配到边缘节点,这些节点随后与观众连接。通常,这些CDN节点使用例如应用层组播和缓存等,形成一个(多层)覆盖树,叶子节点服务客户端和内部节点传播内容到叶子。然而,这对中央处理系统和内部节点造成了巨大的压力,它们必须根据流的数量进行伸缩。这对于有严格延迟约束的直播流来说尤其具有挑战性,因为流需要两次遍历传递树的深度。事实上,树形结构覆盖没有达到低延迟直播服务对CDN延迟的严格要求。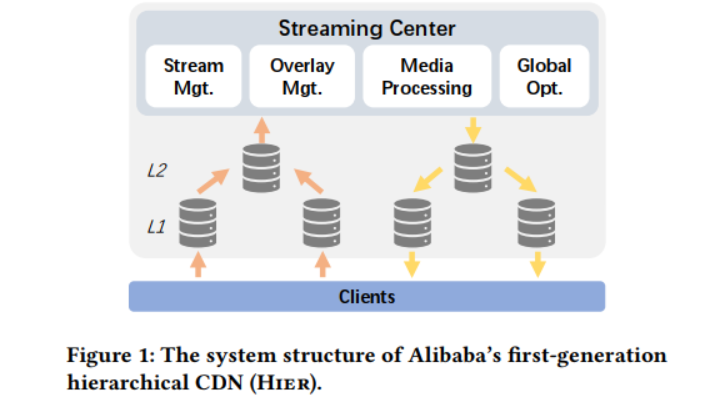 >设计 LiveNet——阿里巴巴基于扁平CDN结构的集中协调低延迟视频网络。下面介绍了基于作者之前的操作经验的三个主要设计选择: 为了摆脱僵化的覆盖拓扑或节点的预先分配角色,LiveNet建立在一个平面CDN上。它的核心是一组灵活的节点(每个节点都是一组机器),它们可以服务于多个动态分配的角色:生产者(接收和处理广播者的流),消费者(接收客户端的请求并对流进行精细控制),以及中继器(将消费者和生产者以任意覆盖的拓扑结构连接起来,提供转发和缓存等服务)。通过将各个节点与任何特定角色解耦,就可以在每个应用程序的基础上组成最合适的覆盖拓扑,并平均分配负载,避免了之前的中心热点。 这种灵活性自然伴随着许多资源分配和管理挑战,特别是在大规模操作时。因此,第二个设计选择借鉴了软件定义网络(
SDN): 作者没有在每个节点中嵌入控制逻辑,而是设计了一个逻辑集中的CDN
控制器(流大脑),负责为节点指定角色,计算它们之间的叠加路径,并为消费节点选择路径。通过在逻辑上集中管理功能,可以轻松地试验新的拓扑和配置,以绕过有问题的节点或实现每个应用程序的策略。前两个设计可以参考下图。
>设计 LiveNet——阿里巴巴基于扁平CDN结构的集中协调低延迟视频网络。下面介绍了基于作者之前的操作经验的三个主要设计选择: 为了摆脱僵化的覆盖拓扑或节点的预先分配角色,LiveNet建立在一个平面CDN上。它的核心是一组灵活的节点(每个节点都是一组机器),它们可以服务于多个动态分配的角色:生产者(接收和处理广播者的流),消费者(接收客户端的请求并对流进行精细控制),以及中继器(将消费者和生产者以任意覆盖的拓扑结构连接起来,提供转发和缓存等服务)。通过将各个节点与任何特定角色解耦,就可以在每个应用程序的基础上组成最合适的覆盖拓扑,并平均分配负载,避免了之前的中心热点。 这种灵活性自然伴随着许多资源分配和管理挑战,特别是在大规模操作时。因此,第二个设计选择借鉴了软件定义网络(
SDN): 作者没有在每个节点中嵌入控制逻辑,而是设计了一个逻辑集中的CDN
控制器(流大脑),负责为节点指定角色,计算它们之间的叠加路径,并为消费节点选择路径。通过在逻辑上集中管理功能,可以轻松地试验新的拓扑和配置,以绕过有问题的节点或实现每个应用程序的策略。前两个设计可以参考下图。
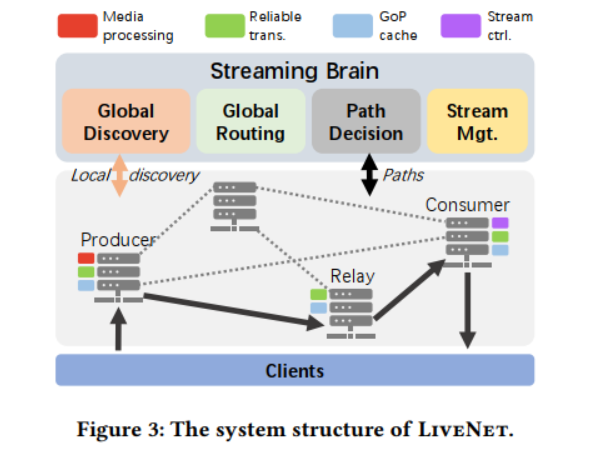 尽管上述架构允许在每一跳(例如,缓存、转码等)灵活地组合新的覆盖拓扑和嵌入式服务,但它也引入了具有挑战性的开销。这是因为数据包必须遍历多个软件栈,给直播客户带来了不必要的延迟。为了缓解这种情况,第三种设计选择使用了一种新颖的流转发机制,目的是最小化端到端延迟。它基于每个节点内的两条并行包处理路径——一条快路和一条慢路,实现了不同协议堆栈层提供的不同功能。在该模型中,每个节点在接收到RTP数据包后,立即将其转发到覆盖层的下一跳,而无需执行传统的控制功能,如丢失检测或拥塞控制(快速路径)。并行地,数据包的一个副本被复制到慢路径上,这引入了拥塞控制和在快速路径发生丢失时的丢失恢复,并在每个节点上实现GoP (Group of Pictures)缓存。这优化了LiveNet的延迟——快速路径以尽可能快的速度交付数据包,而慢路径提供了可靠的传输和内容缓存,这对快速启动和恢复至关重要。流程可参考下图。
尽管上述架构允许在每一跳(例如,缓存、转码等)灵活地组合新的覆盖拓扑和嵌入式服务,但它也引入了具有挑战性的开销。这是因为数据包必须遍历多个软件栈,给直播客户带来了不必要的延迟。为了缓解这种情况,第三种设计选择使用了一种新颖的流转发机制,目的是最小化端到端延迟。它基于每个节点内的两条并行包处理路径——一条快路和一条慢路,实现了不同协议堆栈层提供的不同功能。在该模型中,每个节点在接收到RTP数据包后,立即将其转发到覆盖层的下一跳,而无需执行传统的控制功能,如丢失检测或拥塞控制(快速路径)。并行地,数据包的一个副本被复制到慢路径上,这引入了拥塞控制和在快速路径发生丢失时的丢失恢复,并在每个节点上实现GoP (Group of Pictures)缓存。这优化了LiveNet的延迟——快速路径以尽可能快的速度交付数据包,而慢路径提供了可靠的传输和内容缓存,这对快速启动和恢复至关重要。流程可参考下图。
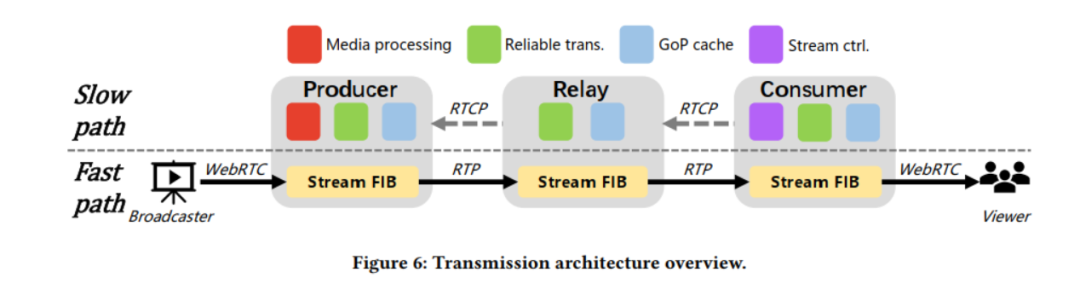 >性能 3年来,LiveNet一直是阿里巴巴低延迟流媒体技术的基础。与之前的分层CDN相比,LiveNet将平均传输路径长度(即覆盖跳数)从4压缩到2,并将CDN的入口和出口点之间的延迟减少了50%以上。它还显著提高了用户可感知的体验:95%的视图的启动延迟小于1秒,98%的视图没有档位。LiveNet的设计选择和经验教训可以广泛应用于其他大型流媒体场景,如视频会议和在线教育。
>个人观点 这篇文章描述了一个名为LiveNet的新型直播传输网络,它已经在阿里巴巴运营了几年,旨在实现低延迟的同时播放高质量的视频这两者的平衡。此外,作为一篇经验论文,从部署和操作LiveNet中学到的经验教训对学术界很有价值。论文对低延迟直播的关注对下一代在线媒体服务具有重要意义,并将激发社区在这一重要领域的更多研究。
>性能 3年来,LiveNet一直是阿里巴巴低延迟流媒体技术的基础。与之前的分层CDN相比,LiveNet将平均传输路径长度(即覆盖跳数)从4压缩到2,并将CDN的入口和出口点之间的延迟减少了50%以上。它还显著提高了用户可感知的体验:95%的视图的启动延迟小于1秒,98%的视图没有档位。LiveNet的设计选择和经验教训可以广泛应用于其他大型流媒体场景,如视频会议和在线教育。
>个人观点 这篇文章描述了一个名为LiveNet的新型直播传输网络,它已经在阿里巴巴运营了几年,旨在实现低延迟的同时播放高质量的视频这两者的平衡。此外,作为一篇经验论文,从部署和操作LiveNet中学到的经验教训对学术界很有价值。论文对低延迟直播的关注对下一代在线媒体服务具有重要意义,并将激发社区在这一重要领域的更多研究。
GSO-simulcast: global stream orchestration in simulcast video conferencing systems
Xianshang Lin, Yunfei Ma, Junshao Zhang, Yao Cui, Jing Li, Shi Bai, Ziyue Zhang, Dennis Cai, Hongqiang Harry Liu, Ming Zhang (Alibaba Group)
本文来自于阿里巴巴的研究者,主要研究的是大规模视频会议系统下,传统的方法无法同时提供1. 较好的视频质量;2. 改善较慢参与者的表现;3.应用于任何可接入会议的设备;的问题,并尝试使用联播 (Simulcast) 的方式,提供一个可以任意设备接入的,具有较好的会议质量,同时不会因为较慢参与者而导致整体表现不佳的系统。 >背景与问题 这个时代,在线视频会议已经成为了一个日常生活的重要组成部分,在线会议,远程授课等场景十分常见。而这种大规模的多方在线会议,带来了两个问题:1)不同的参与者,网络状态是不同的。2)参与者间的订阅关系是复杂的。传统的设计主要集中于以下三个方案: 代码转换:代码转换(transcoding)可以给下游网络路径提供适配的视频流,但在大规模场景中,对服务器的性能具有较高的需求,在昂贵的花销上是不合算的。 SVC:SVC可以把一个流适配到多种比特率上,但SVC的问题是它严重依赖于编解码方案,而部分终端不具备对于SVC的编解码能力。 联播:联播 (Simulcast) 可以将视频流编码成多种比特率,并且并行发送。但是,传统的联播方法,没有对于链路间和参与者的协调,流策略也不够灵活,导致视频和网络之间的失配,以及大规模网络下的低可管理性。 在传统的设计下,联播无法满足大规模多方会议的需求,那么,就需要全局的 信息进行参与者的协调与流策略的设置,这就带来了以下几个挑战:1)如何实现实时的控制。2)如何对不同的流进行优先级的管理。3)如何获取全局的信息。4)可以利用现有的架构进行实现。 >设计 本文认为,是全局信息的缺失与流策略的僵硬,导致联播方式的较差表现。因此,本文提出了GSO-Simulcast,通过全局信息进行流策略管理。从而满足以下三个目标,即1)更低的链路拥塞。2)更少的视频和网络失配状况。3)更好的流策略。为此,本文提出了一个三层的网络架构,如下图所示: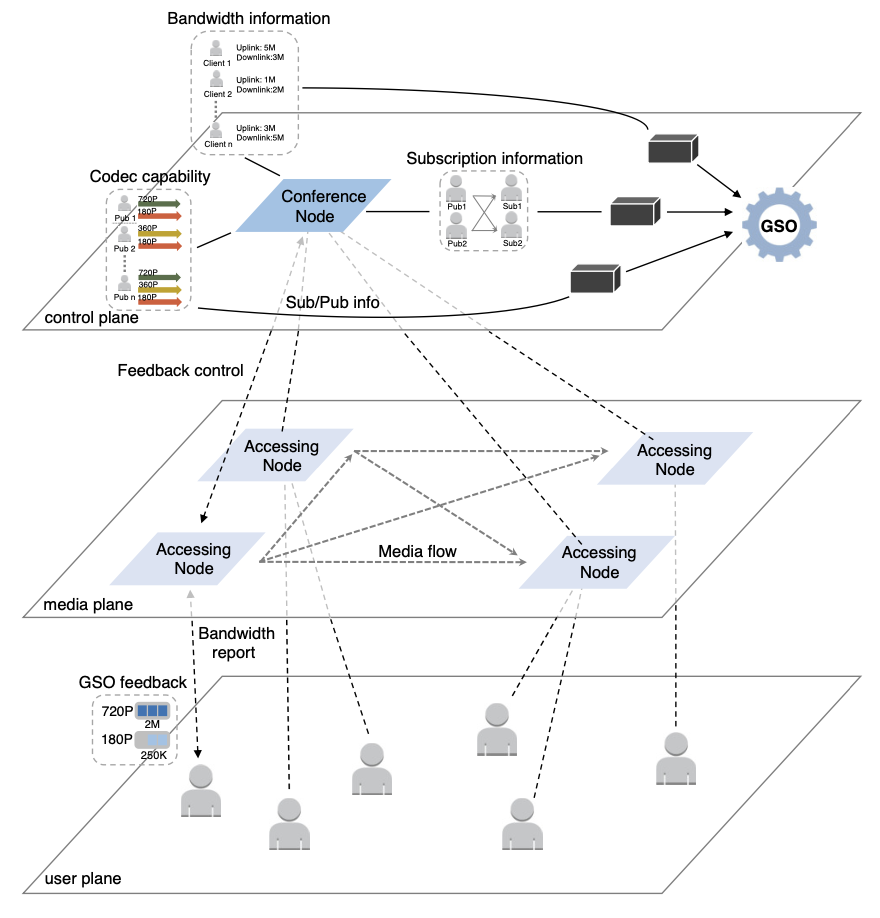 控制算法:本文将问题设置为一个优化问题,并以三部分作为限制条件,分别是:1)带宽的限制。2)编解码能力的限制。3)订阅的限制。而这三部分,则是对应背包,合并,规约三部分算法。控制算法通过多次迭代计算,从而快速得到对应的解。
获取全局信息:为了实现中心化的方案,本文从多个方面获取不同的全局信息:1)订阅信息的收集可以通过
信号信道进行传播。2)编解码信息则是在SDP协商时发送的,这包括了一些附加信息,用来收集分辨率和比特率。3)在发送端可以直接获取带宽信息,而在接受端则利用RTCP进行带宽计算。
反馈控制:当控制器找到了新的解决方案,则会想参与者发送控制反馈以配置流。配置流的信息是在TMMbr中携带的,并以TMMBN作为接受反馈。以这种带内的方法来提高反馈的及时性。
管理流:1)对于流的优先级,我们可以给一些流更高的QoE优先级,从而确保该流能被分配尽可能多的带宽。2)对于同一个发送者的多个流,我们可以重用控制算法的第一部分,将其作为两个独立的流,在后续部分合并,进行统一的调度分配。
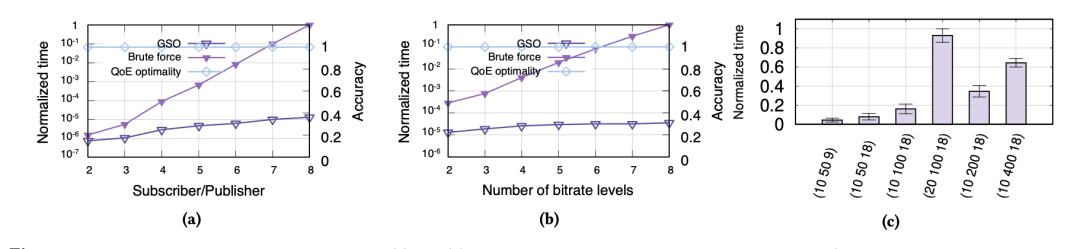
>性能 GSO-Simulacst获得了较好的性能表现。如下图所示,(a)表示GSO-Simulcast方法具有较好的性能表现,而线性的增长表示大规模的参与者场景也具有较好的表现。(b)则表示在不同比特率下, 该方面都有较好的表现。(c)则表示,随着比特率或者参与者的线性增长,整体的时间也是在线性增长的,也就是体现了较好的可扩展性。其中,元组被表示为(#放映者,#参与者,#比特率)。
控制算法:本文将问题设置为一个优化问题,并以三部分作为限制条件,分别是:1)带宽的限制。2)编解码能力的限制。3)订阅的限制。而这三部分,则是对应背包,合并,规约三部分算法。控制算法通过多次迭代计算,从而快速得到对应的解。
获取全局信息:为了实现中心化的方案,本文从多个方面获取不同的全局信息:1)订阅信息的收集可以通过
信号信道进行传播。2)编解码信息则是在SDP协商时发送的,这包括了一些附加信息,用来收集分辨率和比特率。3)在发送端可以直接获取带宽信息,而在接受端则利用RTCP进行带宽计算。
反馈控制:当控制器找到了新的解决方案,则会想参与者发送控制反馈以配置流。配置流的信息是在TMMbr中携带的,并以TMMBN作为接受反馈。以这种带内的方法来提高反馈的及时性。
管理流:1)对于流的优先级,我们可以给一些流更高的QoE优先级,从而确保该流能被分配尽可能多的带宽。2)对于同一个发送者的多个流,我们可以重用控制算法的第一部分,将其作为两个独立的流,在后续部分合并,进行统一的调度分配。
>性能 GSO-Simulacst获得了较好的性能表现。如下图所示,(a)表示GSO-Simulcast方法具有较好的性能表现,而线性的增长表示大规模的参与者场景也具有较好的表现。(b)则表示在不同比特率下, 该方面都有较好的表现。(c)则表示,随着比特率或者参与者的线性增长,整体的时间也是在线性增长的,也就是体现了较好的可扩展性。其中,元组被表示为(#放映者,#参与者,#比特率)。
 >个人观点 本文主要解决的问题是在多方视频会议下表现较差的问题。为了设备的兼容性,本文采用了联播的方式进行设计,并通过多层的网络架构与集中式的调度器进行流策略的管理。而通过不改变网络本身的架构,该系统得到了较好的表现。但是,本文的整体设计主要依赖于集中式的控制器,而将其推广到分布式的设计也是一个可行的思路。
>个人观点 本文主要解决的问题是在多方视频会议下表现较差的问题。为了设备的兼容性,本文采用了联播的方式进行设计,并通过多层的网络架构与集中式的调度器进行流策略的管理。而通过不改变网络本身的架构,该系统得到了较好的表现。但是,本文的整体设计主要依赖于集中式的控制器,而将其推广到分布式的设计也是一个可行的思路。
编辑:黄飞

















