在这种背景下,基于FPGA的高速路由查找算法应运而生。FPGA(现场可编程门阵列)是一种高度集成的可编程硬件,它能够在查找过程中发挥硬件的高效性。本研究采用了一种分段查找与前缀扩展技术相结合的算法,将IPv4的32位IP地址分为四段,每段存储在一个物理地址连续的内存区域中,这样做的目的是减少存储空间的访问次数,从而加快查找速度。
算法的核心在于四级流水线的并行处理结构,每一级流水线负责处理IP地址的一个段,实现了存储器访问次数的减少和查找速度的提升。各级流水线之间通过寄存器传递数据,每个流水线都能够独立地从输入端或寄存器读取数据,解析IP地址,计算存储器访问地址,完成数据的读写。
为了确保并行处理结构中各级的容量均衡,并最小化存储空间的占用,本研究引入了动态规划算法来确定各级的分割点。动态规划算法能够计算出在不同前缀长度下所需的最小前缀扩展数,以达到最优的存储空间利用和查找效率。
除了查找算法的创新,FPGA的硬件结构设计也是本研究的重点。基于FPGA的并行处理结构包含了存储器模块、查找模块和更新模块。存储器模块用于存放路由表数据,查找模块负责实现查找功能,更新模块则用于更新路由信息。这种设计不仅支持高速查找,还能够动态地更新路由表项。
实验结果表明,该算法在Stratix系列芯片上实现,并使用Verilog硬件描述语言和Quartus II开发平台进行设计后,能够实现每秒10亿次以上的查找速度,足以支持20Gbps的链路速率。
总结来说,本研究提出的基于FPGA和前缀扩展技术的分段快速路由查找算法,以其快速查找、支持动态更新和易于实现的优点,非常适合高速路由器的查找需求,为未来网络传输的高效性提供了可靠的技术支持。
对基于FPGA的高速路由查找算法的研究

0 引言
随着网络流量的不断增加和路由表容量的不断增大,路由查找已经成为制约因特网的主要瓶颈。尽管采用CIDR技术能产生聚集路由,但路由器的路由表项还是很大,使得路由查找成为高速路由器的瓶颈。因此,提高路由查找速度已成为高速路由器的关键技术。
目前实现路由查表的方法主要有软件和硬件两类。其中基于软件查表方法的查找次数最少为5次,这显然已经不能满足高速链路的要求;而基于Cache的查找方法,其查找依赖于流量的模式,即IP数据流具有局部性,随着网络数据量的增大,命中率也会降低。而基于硬件的Stanford算法则结构简单,易于硬件实现,而且查找速度快,其最少需要访问一次存储器,最多需要访问2次存储器。但其占用存储空间大(为33 MB),表项更新单元数多。在最坏情况下,更新一个表项需要操作64 k个存储单元。
本文采用多表结构,将查找过程分为4级。
因为采用串行查找实现时,查找一个IP数据包最少需要访问一次存储器,最多需要访问4次。而根据四块存储器独立工作的特性,采用流水线的方式进行并行化设计,则可以保证访问一次存储器就能完成一次数据包的查找。为了保证占用较小的空间且四个存储块的容量相对均衡,本文用一个动态规划算法来求解四个目标层的值。此外,这种设计结构也支持动态更新,并且更新单元数较少。
1 查找算法
本系统的基本算法采用分段查找及前缀扩展技术来将IPv4的32位IP地址分成4段,假设i是其中一段(1≤i≤4),length i代表第i段所对应的IP地址长度。每一段内容存储在一块物理地址连续的内存区域中,称为TBLi。那么,在第一段区域TBL1中,使用前缀扩展技术,即可把所有长度小于等于length1的前缀扩展成长度为length1的前缀。图1所示是该四级路由算法的结构框图。
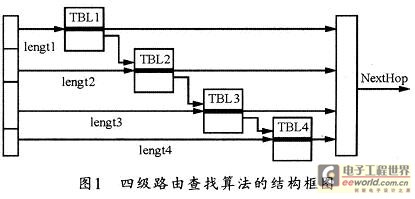
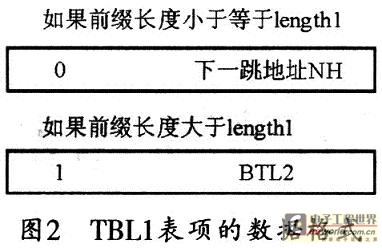
显然,该结构中的第一段有2length1个表项,析出IP地址的前length1位的值为第一块内存的偏移地址,其对应表项的数据格式如图2所示。若前缀长度小于等于length1,则表项的第一位标识为0,其余bit位表示下一跳的转发信息。若前缀长度大于length1,则表项的第一位标识为1,其余位填写扩展表的索引值可以作为指向TBL2的指针。在其余的三个段中,可采用同样的方法进行前缀扩展。
本算法的查找过程是在匹配一个IP地址时,从第一段开始进行分段查找,每查找一段,则解析出对应段长度的IP,并取相应内存区域的地址。例如进行第二段查找时,可将其值作为偏移量,再加上相应的基址,就可获得该段对length1+1位开始,然后解析出length2长度的IP地址作为偏移量。之后再用TBL1表项里的索引,将其左移length2位作为基址,这样就确定了第二块连续存储区域中的地址。依次类推,分段查找,直到找到下一跳地址为止。
本算法的插入过程与查找过程相似,先根据前缀对应的分段和索引查找到对应的子表,然后在其涉及的范围内读取各个表项,再根据表项的值确定是否用新的路由前缀信息覆盖该表项。如果在此过程中,该表没有相应的段空间,则需分配对应的存储空间。若该段空间为空,则收回该存储空间。
2 目标层的确定
在用NT(k,ω)表示前缀长度为w的情况下,还需要找出k个目标层时对应的最小前缀扩展数。这样,其最优解就是NT(k,ω)。其递推公式如下:
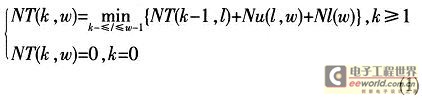
式中,Nu(l,ω)表示将l+1层至ω-1层扩展到ω层的前缀数目,其中若某一层不存在,则将那一层直接忽略。另外,在扩展时还要考虑前缀捕获问题。Nl(ω)是ω层原有的前缀数目。
3 硬件结构
依据该算法设计出的基于4级流水线的并行处理结构如图3所示,该结构分为存储器模块、查找模块和更新模块三个部分。4个存储模块可存储对应表TBL中的数据;查找模块可通过读取对应存储模块中的数据实现查找;更新模块则可将要更新的路由信息添加到对应的存储块中。
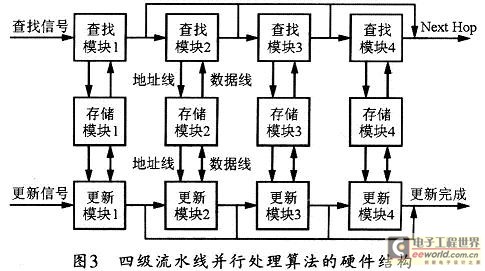
在FPGA设计时,每个查找模块都是一个硬件逻辑块,每两个查找模块间都有一个寄存器用以传输数据,每个查找模块都可从输入端或寄存器中读取信息,并解析出IP地址中的相应位,然后计算存储器的访问地址,访问存储器获取数据,并将数据写入寄存器或者输出端。四个查找模块按流水线的工作方式进行处理,能够达到访问一次存储器处理一个IP数据包。
4 实验结果分析
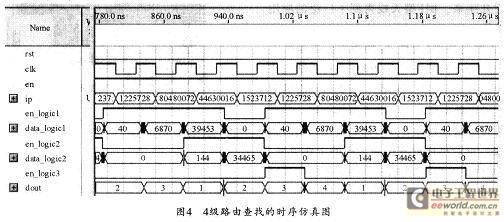
通过对BGP Table中前缀的长度进行分析和统计,可模拟生成50,000条前缀。然后用动态规划求出4个目标层(20,22,24和32)来进行实验分析。实验可采用Stratix系列芯片,并利用Ver-ilog硬件描述语言和QuartusII开发平台进行设计、综合、布局布线,然后在静态时序分析后进行仿真,其时序仿真结果如图4所示。由于查找需要一个时钟周期,而时钟频率为100MHz,所以,每秒可以完成100M次查找。若IP分组为40B长,则可以满足20Gbps的链路速率。
5 结束语
本文给出了一种基于前缀扩展的分段快速路由查找算法。该算法可以结合硬件实现的优点,并运用多级流水线处理方法,因而具有查找速度快、支持动态更新和实现简单等优点,十分适合于20 Gbps核心路由器环境下的查找机制。