NVLink,是NVIDIA公司开发的一种高速连接接口,主要用于连接NVIDIA的GPU(图形处理器)和CPU(中央处理器),以及GPU之间的通信。NVLink通过提供高带宽、低延迟的数据传输能力,优化了GPU之间的数据交互,极大地提升了系统性能。
NVLink采用了高速串行接口设计,支持双向数据传输,带宽可以达到高达100Gbps。这种设计使得NVLink在处理大量数据和复杂计算任务时,能够提供更高的数据吞吐量和更低的通信延迟。
NVLink支持多级互联,即多个GPU可以通过NVLink相互连接,形成一个高性能的计算集群。这种设计使得NVLink在数据中心和服务器应用中尤为重要,特别是在高性能计算(HPC)、人工智能(AI)和大数据处理等领域。
NVLink的物理接口采用了高密度的信号传输技术,可以支持多种接口类型,如PCIe和NVMe,使得NVLink在兼容性和扩展性方面具有优势。
随着NVIDIA产品线的不断发展,NVLink技术也在不断进步。从最初的NVLink 1.0发展到NVLink 3.0,带宽和性能都有显著提升,进一步满足了各种高性能计算应用的需求。

NVLink技术之GPU与GPU的通信-在多 GPU 系统内部,GPU 间通信的带宽通常在数百GB/s以上,PCIe总线的数据传输速率容易成为瓶颈,且PCIe链路接口的串并转换会产生较大延时,影响GPU并行计算的效率和性能。
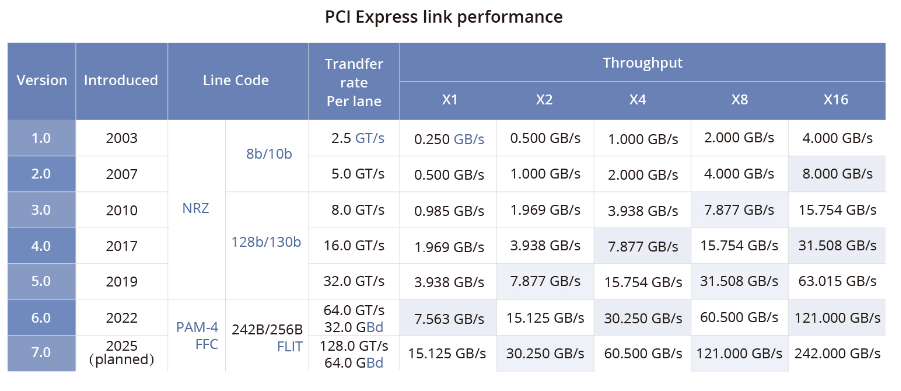
什么是NVIDIA?InfiniBand网络VSNVLink网络-NVSwitch物理交换机将多个NVLink GPU服务器连接成一个大型Fabric网络,即NVLink网络,解决了GPU之间的高速通信带宽和效率问题。
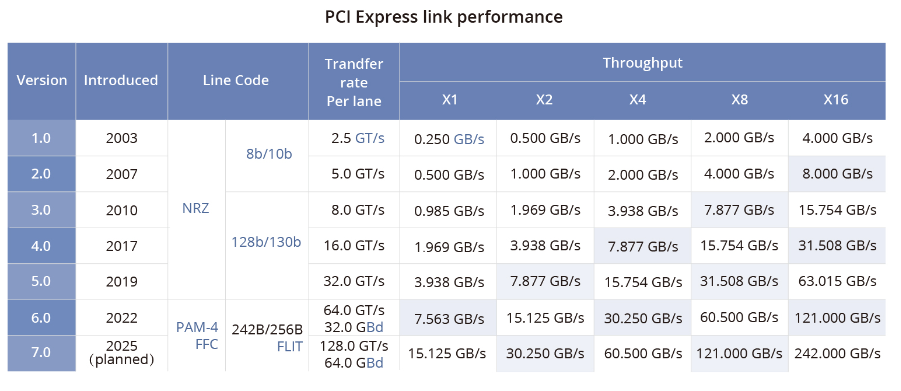
全面解读英伟达NVLink技术-NVLink是一种解决服务器内GPU之间通信限制的协议。与传统的PCIe交换机不同,NVLink带宽有限,可以在服务器内的GPU之间实现高速直接互连。第四代NVLink提供更高的带宽,每条通道达到112Gbps,比PCIe Gen5通道速率快三倍。
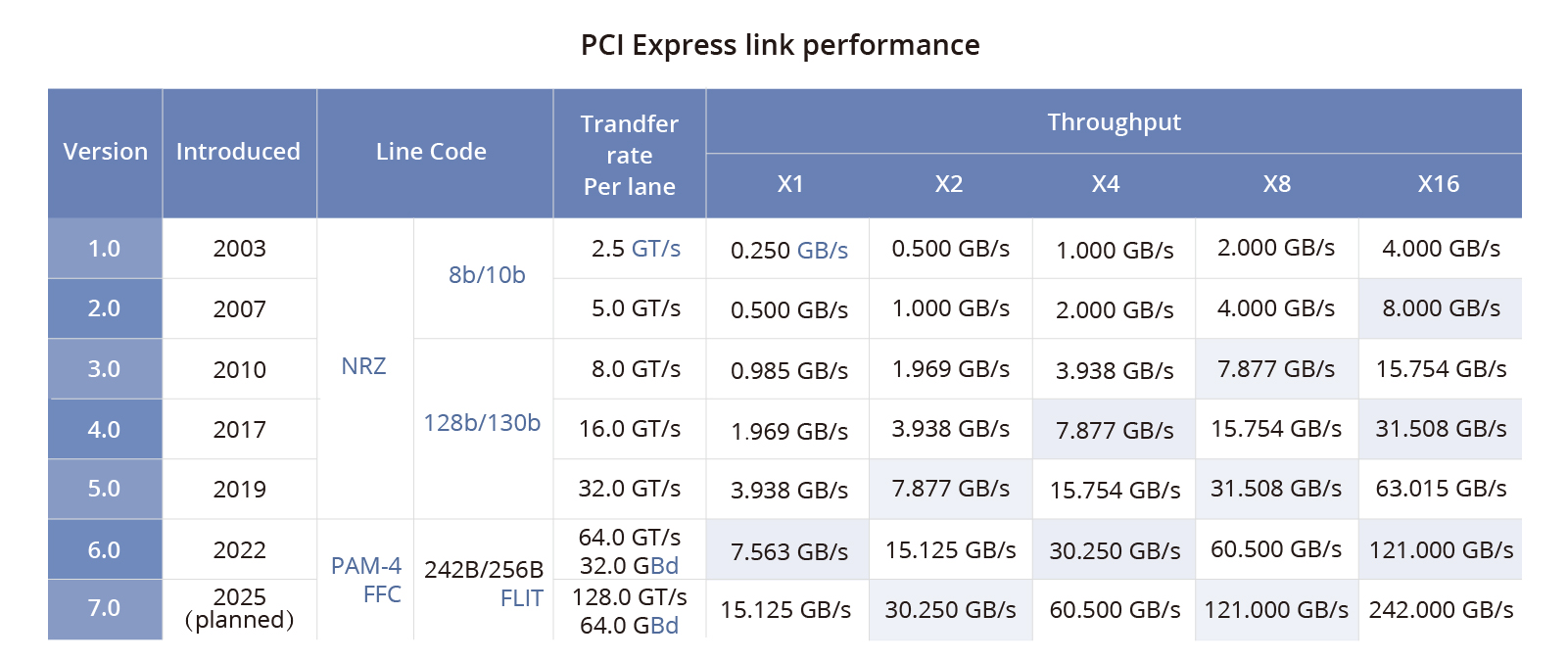
NVIDIA NVLink技术已成为高性能计算领域的关键,通过解决服务器内GPU通信限制,提供高速直接互连。第四代NVLink带宽高达112Gbps,比PCIe Gen5快三倍。NVSwitch芯片和NVLink服务器利用此技术,显著提升通信和带宽,支持900 GB/s的GPU互连。NVLink交换机进一步扩展应用,连接多服务器GPU,构建大型Fabric网络,优化数据传输和安全性。与传统以太网和...
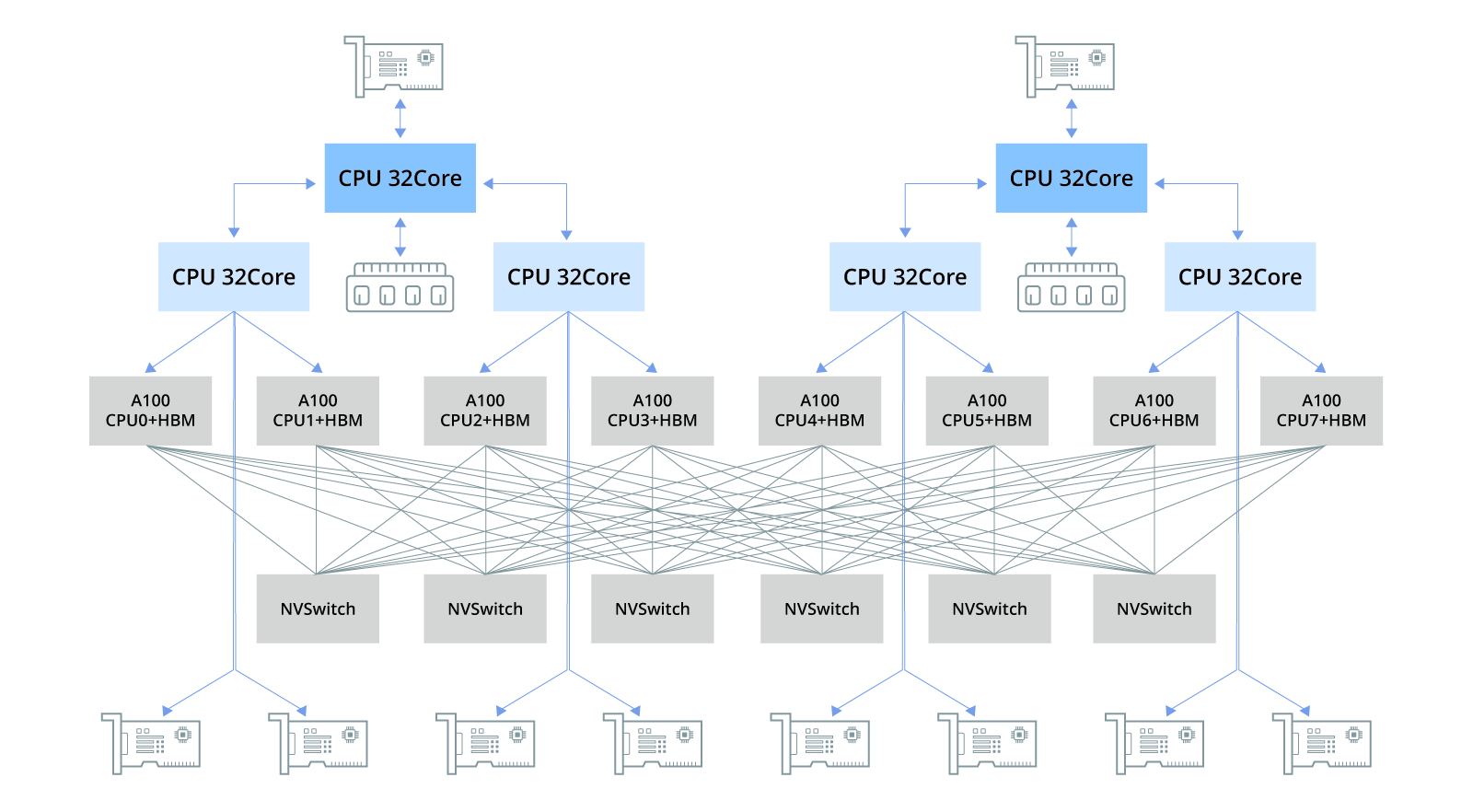
在大规模模型训练领域,高性能GPU服务器基础架构通常由搭载多块GPU(如A100、H100等)的集群系统构成。PCIe总线及交换机芯片实现各组件高效连接,NVLink技术则用于CPU与GPU间及GPU间的点对点连接,历经多代演进,显著提升数据传输速度和带宽性能。NVSwitch芯片支持主机内多GPU低延迟通信,而NVLink交换机则解决跨主机GPU连接问题。此外,高带宽内存(HBM)技术突破传统内...

本文探讨了汽车自动驾驶中AI运算的基本流程,重点分析了CPU与GPU之间的数据传输瓶颈。英伟达通过GPU Direct和NVLink技术逐步解决这一问题,显著提升传输效率。对比PCIe和NVLink,后者在带宽和性能上遥遥领先,但成本较高。车载领域多采用千兆以太网,存在严重瓶颈。英伟达通过NVLink Switch构建大规模计算节点,形成技术护城河。AMD的Infinity Fabric技术在多芯...

八家公司联合推出新一代AI数据中心网络互联技术UALink,旨在打破Nvidia的NVLink垄断。UALink通过开放标准提升AI加速器间通信效率,支持多厂商加速器协同工作。Nvidia凭借GPU和NVLink技术在市场占据领先地位,但竞争对手通过开放标准如Ultra Ethernet和UALink反击。UALink预计2024年第三季度发布1.0版规范,支持1024个加速器互联。此举有助于构建...

英伟达的NVLink技术在GPU网络通信中占据重要地位,但其封闭性限制了其他厂商发展。为此,谷歌、Meta、微软等八大科技巨头联合成立UALink联盟,旨在开发开放的AI数据中心GPU网络通信标准,打破英伟达垄断。UALink支持高带宽、低延迟的跨节点扩展,预计将提升AI计算性能与效率。此举为AMD、英特尔等公司提供发展机遇,博通等可生产UALink交换机。微软、谷歌、Meta等大公司期望通过UA...

本文探讨了流行的GPU/TPU集群网络技术,包括NVLink、InfiniBand、ROCE以太网和DDC网络方案,分析了它们在LLM训练中的连接方式和作用,以及各自的优缺点和适用场景。

本文主要探讨了流行的GPU/TPU集群网络组网技术,包括NVLink、InfiniBand、ROCE以太网Fabric和DDC网络方案。文章分析了每种技术的优缺点,例如NVLink和InfiniBand的性能优势,但扩展性和成本问题;ROCE以太网的优势在于成熟的生态系统和较低的组网成本,但其拥塞控制机制可能不如IB和NVLink;DDC全调度网络则在解决以太网拥塞问题上具有显著优势,但其成本和供...

流行的GPU/TPU集群网络组网技术包括NVLink、InfiniBand、ROCE以太网Fabric和DDC网络方案等。它们在LLM训练中发挥着重要作用,其中NVLink具有高性能和低开销的特点,但受限于GPU规模;InfiniBand提供卓越的速度和低延迟,但成本较高且扩展性有限;ROCE无损以太网以其成熟的生态、低成本和快速带宽迭代速度,在中大型训练GPU集群中更具优势;DDC全调度网络结合...









