首先是一个功能强大的汉字转拼音工具。它能将中文字符转换成相应的拼音,广泛用于汉字注音、排序和检索等任务。这款工具的智能化程度很高,可以根据词组智能匹配最准确的拼音,同时支持多音字。对于繁体中文和注音,它也提供了相应的支持。更为便捷的是,它支持多种不同的拼音和注音风格,满足不同用户的需求。
该工具的版本众多,涵盖了JavaScript、Python、Go和Rust等多种编程语言。以Node.js/JavaScript版本为例,它能够在Node环境和Web浏览器环境中运行,其作者hotoo在GitHub上提供了详细的资源和代码。Python版本由mozillazg开发,同样可在GitHub上找到相关资源。Go和Rust版本的开发者也是mozillazg,适配了不同的开发环境。
使用过程中,有些细节需要注意。例如,根据《汉语拼音方案》,y、w、ü(yu)并不是声母,所以在声母风格下,这些字母不会被显示。如果需要把它们当作声母,可以通过设置参数来调整。此外,该工具的数据来源于pinyin-data和phrase-pinyin-data,这些数据对单个汉字和词组的拼音转换都至关重要。
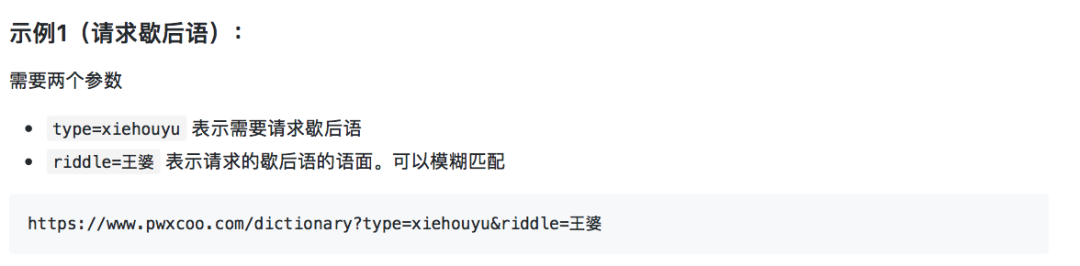
另一个值得推荐的资源是新华字典的API。这个API包含了海量的中文语言数据,包括14032条歇后语,16142个汉字,264434个词语,以及31648个成语。开发者原本是为了实现成语接龙游戏,在没有现成的数据库可用的情况下,自行搜集和整理了这些数据。他把这些数据放在了GitHub上,既方便自己使用,也供其他有类似需求的人士使用。
新华字典API的数据分为成语、词语、汉字和歇后语四部分,每部分都提供了相应的JSON文件。这些数据不仅丰富,而且通过API接口可以方便地被应用在各种项目中。
通过这两个工具,我们可以看到开源社区的力量。无论是汉字转拼音工具还是新华字典API,都是社区成员的贡献,它们使得中文语言处理变得更加简单和高效。我们鼓励大家充分利用这些资源,并且在可能的情况下,为开源社区做出自己的贡献。在未来,随着技术的进步和社区的壮大,相信会有更多优秀的中文处理工具诞生。
【导读】平常为大家推荐的资源中,以英语语言占据大多数。今天 特别要为大家推荐两个跟中文相关的资源工具。先简单介绍下这两个资源工具都是什么。第一个,汉字转拼音的工具——即将中文字符转换成它的拼音。除了支持 JavaScript,还可以支持 Python、Go、Rust 等多种语言。可以说是非常 nice 的一个中文资源工具了。第二个是新华字典的 API,收录包括 14032 条歇后语,16142 个汉字,264434 个词语,31648 个成语。有需要的同学可以收藏留着用,觉得不错记得分享点赞。

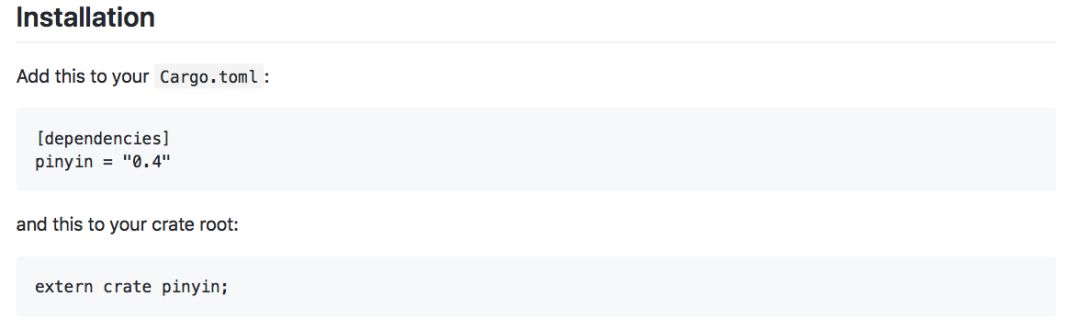
汉字转拼音工具
▌功能
将中文字符转换为拼音。可用于汉字注音、排序、检索任务。
▌特性
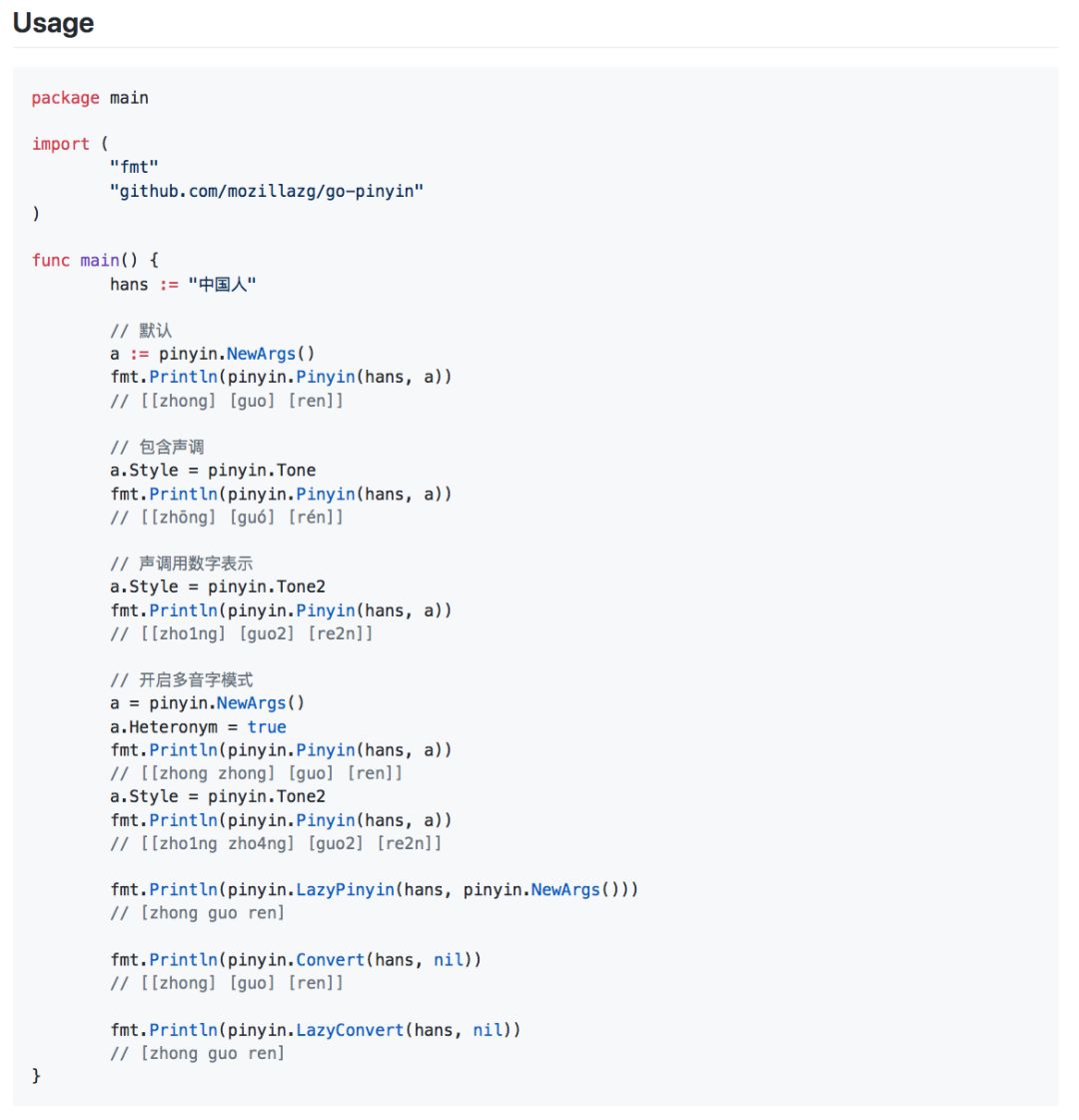
根据词组智能匹配最正确的拼音。
支持多音字。
简单的繁体支持, 注音支持。
支持多种不同拼音/注音风格。
▌支持版本
1.Node.js/JavaScript 版
注:这个版本同时支持在 Node 和 Web 浏览器环境运行;
作者:hotoo;来源:GitHub
HTTPS://github.com/hotoo/pinyin
2.Python 版
作者:mozillazg;来源:GitHub
HTTPs://github.com/mozillazg/python-pinyin
3.Go 版
作者:mozillazg;来源:GitHub
https://github.com/mozillazg/go-pinyin
4.Rust 版
作者:mozillazg;来源:GitHub
https://github.com/mozillazg/rust-pinyin
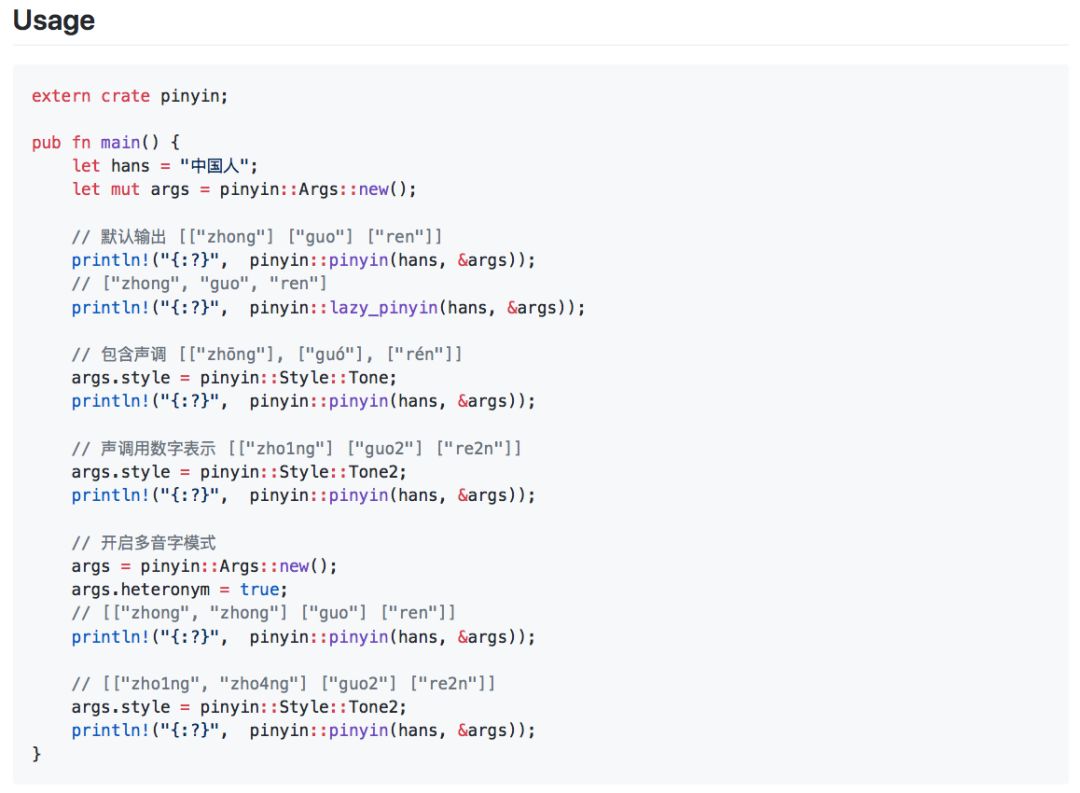
▌一些注意事项
1.为什么没有 y, w, yu 几个声母?
1>>>frompypinyinimportStyle,pinyin2>>>pinyin('下雨天',style=Style.INITIALS)3[['x'],[''],['t']]
因为根据《汉语拼音方案》, y,w,ü (yu) 都不是声母。
声母风格(INITIALS)下,“雨”、“我”、“圆”等汉字返回空字符串,因为根据《汉语拼音方案》, y,w,ü (yu) 都不是声母,在某些特定韵母无声母时,才加上 y 或 w,而 ü 也有其特定规则。 —— @hotoo
如果你觉得这个给你带来了麻烦,那么也请小心一些无声母的汉字(如“啊”、“饿”、“按”、“昂”等)。 这时候你也许需要的是首字母风格(FIRST_LETTER)。 —— @hotoo
参考:
hotoo/pinyin#57,#22,#27,#44
如果觉得这个行为不是你想要的,就是想把 y 当成声母的话,可以指定strict=False, 这个可能会符合你的预期,详见strict 参数的影响
1>>>frompypinyinimportStyle,pinyin2>>>pinyin('下雨天',style=Style.INITIALS)3[['x'],[''],['t']]4>>>pinyin('下雨天',style=Style.INITIALS,strict=False)5[['x'],['y'],['t']]
2.拼音数据
单个汉字的拼音使用pinyin-data的数据
词组的拼音使用phrase-pinyin-data的数据
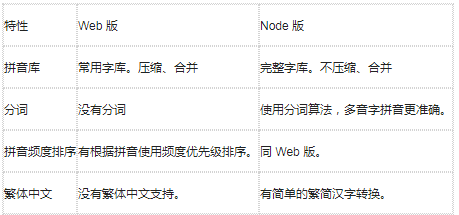
3.node 版和 web 版有什么异同?
pinyin目前可以同时运行在 Node 服务器端和 Web 浏览器端。 API 和使用方式完成一致。但 Web 版较 Node 版稍简单,拼音库只有常用字部分,没有使用分词算法, 并且考虑了网络传输对词库进行了压缩处理。
由于分词和繁体中文的特性,部分情况下的结果也不尽相同。由于这些区别,测试不同运行环境的用例也不尽相同。
更多详细安装与使用教程可访问 GitHub 链接进行访问~
各版本 GitHub 地址:
https://github.com/hotoo/pinyin
https://github.com/mozillazg/python-pinyin
https://github.com/mozillazg/go-pinyin
https://github.com/mozillazg/rust-pinyin
新华字典 API
▌介绍
作者本来的目的是想可以实现成语接龙,苦于没有现成可用的数据库,自己就从各个网站抓取整理了一份。所有的数据都作者从网上找的。放在 Github 是为了方便自己的使用,同时也能方便有类似需求的人不用去做这些 trival 的工作。所有抓取数据的脚本都在仓库里。
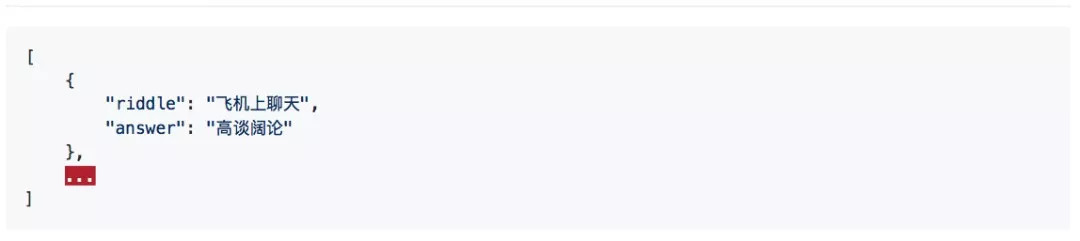
中华新华字典数据库和 API 。收录包括 14032 条歇后语,16142 个汉字,264434 个词语,31648 个成语。所有的数据放在 data/ 目录。

▌数据库与 API 介绍
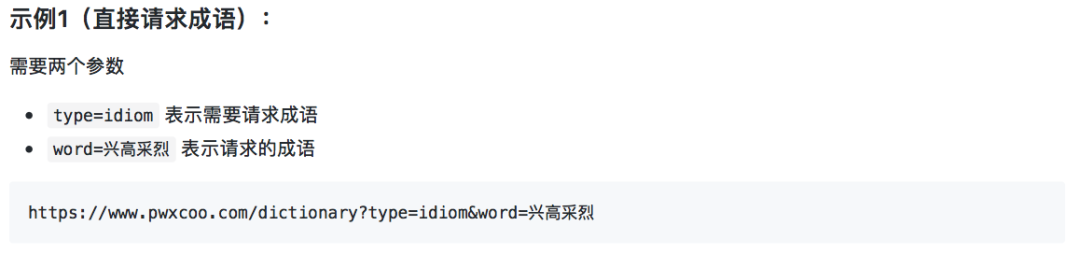
1.成语(idiom.json)

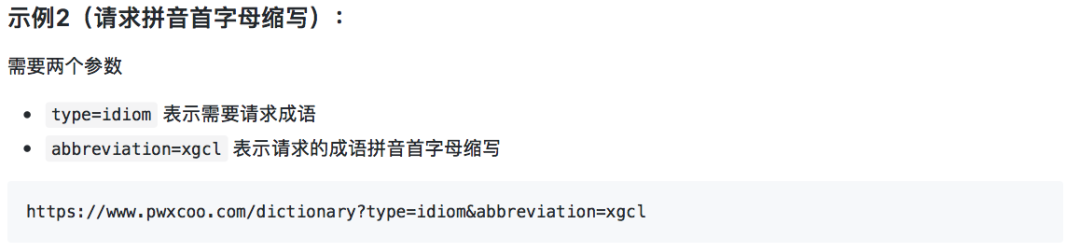
2.词语(ci.json)
3.汉字(word.json)
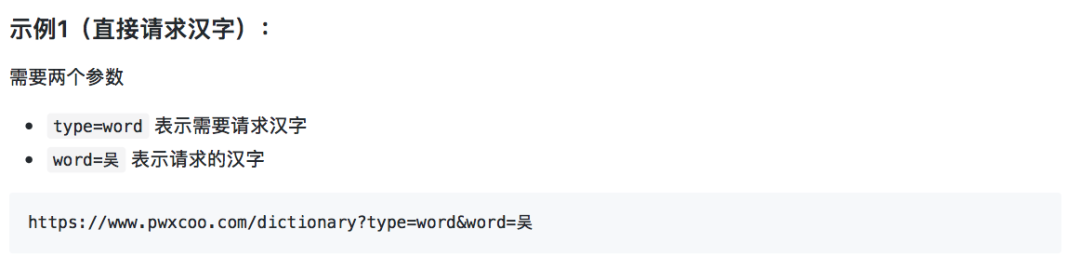
4.歇后语(xiehouyu.json)